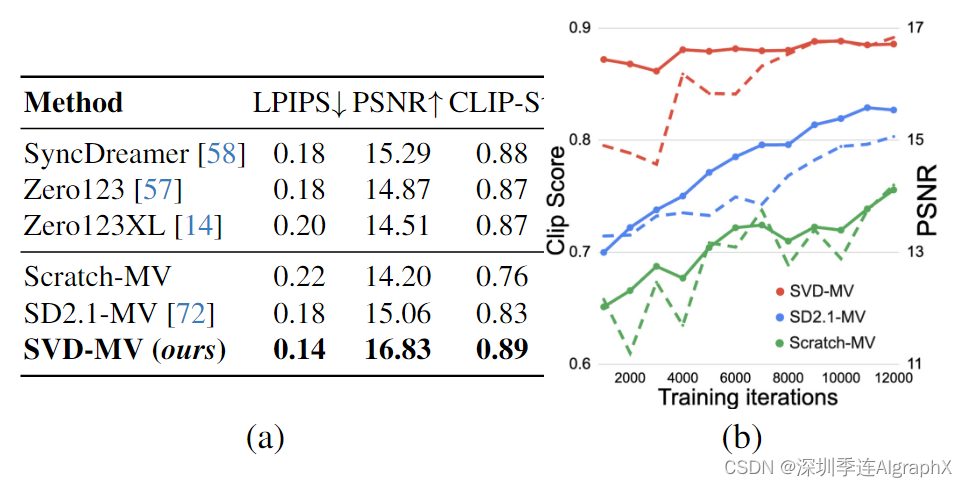
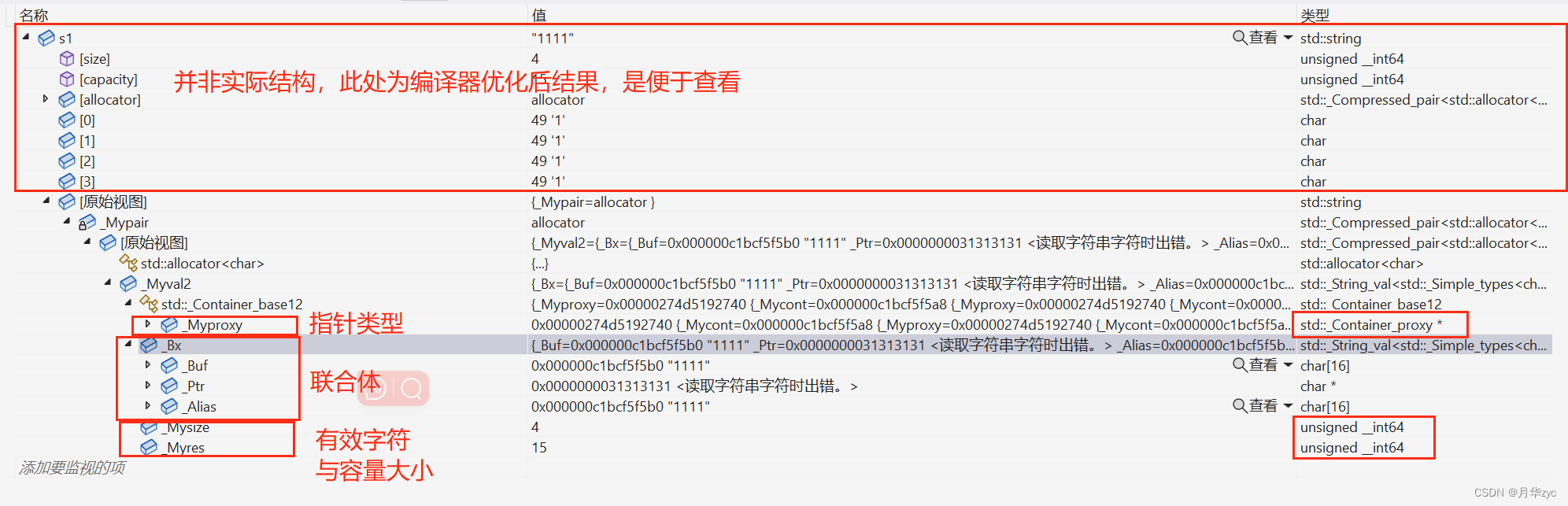
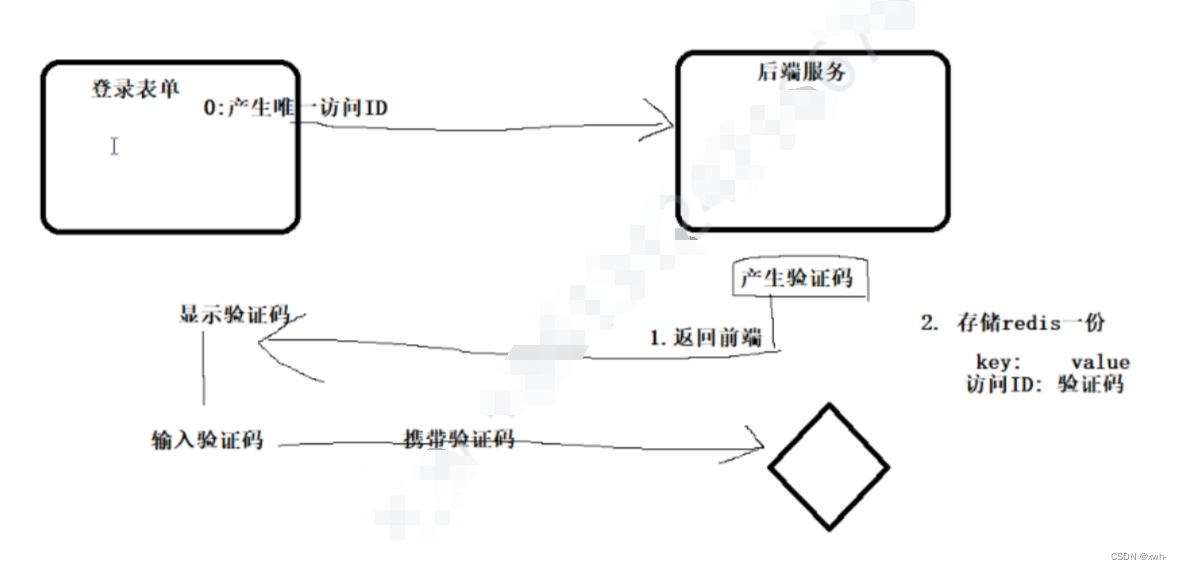
落花雨
你飘摇的美丽
花香氤
把往日情勾起
我愿意
化浮萍躺湖心
只陪你
泛岁月的涟漪
🎵 许嵩《山水之间》
Pandas是一个强大的Python数据分析工具库,它极大地简化了数据处理和分析的过程。无论你是数据科学初学者还是经验丰富的分析师,了解Pandas的基本用法都是提高工作效率的关键。本篇博客将介绍Pandas的几个核心概念和常用功能。
什么是Pandas?
Pandas是一个开源的Python库,提供了高性能的、易于使用的数据结构和数据分析工具。最核心的数据结构是DataFrame,它是一种表格型的数据结构,可以看作是一个二维数组,但是与数组不同,它可以处理不同类型的数据。
安装和导入
要使用Pandas,首先需要确保它已经安装在你的环境中。安装很简单,只需要运行以下命令:
pip install pandas
安装完成后,你可以在Python脚本或交互式环境中导入Pandas:
import pandas as pd
创建和读取数据
你可以从多种数据源中读取数据到DataFrame中,例如CSV文件、Excel文件、SQL查询结果等。
# 从CSV文件读取数据
df = pd.read_csv('data.csv')
# 从Excel文件读取数据
df = pd.read_excel('data.xlsx')
# 查看前几行数据
print(df.head())
也可以手动创建DataFrame:
data = {'Name': ['John', 'Anna', 'Peter', 'Linda'],
'Age': [28, 22, 34, 29],
'City': ['New York', 'Paris', 'Berlin', 'London']}
df = pd.DataFrame(data)
数据探索
一旦你有了一个DataFrame,你可以使用多种方法来探索和检查数据:
# 查看数据维度
print(df.shape)
# 获取列名
print(df.columns)
# 数据统计概览
print(df.describe())
# 查看单列数据类型
print(df['Age'].dtype)
数据选择和过滤
Pandas提供了灵活的方法来选择和过滤数据:
# 选择一列
ages = df['Age']
# 选择多列
sub_df = df[['Name', 'City']]
# 基于条件过滤
older_than_30 = df[df['Age'] > 30]
# 使用loc和iloc选择数据
# loc是基于标签的选择,iloc是基于整数位置的选择
row = df.loc[0] # 选择第一行
row = df.iloc[0] # 同上
数据清洗
数据清洗是数据分析中一个重要的步骤。Pandas提供了许多功能来处理缺失值、重复值、字符串操作等。
# 处理缺失值
df.dropna() # 删除含有缺失值的行
df.fillna(0) # 用0填充缺失值
# 删除重复值
df.drop_duplicates()
# 字符串操作
df['Name'] = df['Name'].str.upper() # 将Name列的字符串转换为大写
数据整理
Pandas能够帮助你整理数据以便于分析:
# 新增列
df['Senior'] = df['Age'] > 60
# 分组聚合
grouped = df.groupby('City')
print(grouped.mean())
# 数据透视表
pivot = pd.pivot_table(df, values='Age', index='City', aggfunc='mean')
print(pivot)
数据合并
你可能需要将来自不同数据源的数据合并在一起:
python
Copy code
# 合并数据框
other_data = {'Name': ['Sara', 'Tom'],
'Age': [25, 35],
'City': ['Rome', 'Madrid']}
other_df = pd.DataFrame(other_data)
combined_df = pd.concat([df, other_df])
# 数据连接
df1 = pd.DataFrame({'Key': ['A', 'B', 'C'], 'Value': [1, 2, 3]})
df2 = pd.DataFrame({'Key': ['B', 'C', 'D'], 'Value': [4, 5, 6]})
joined_df = pd.merge(df1, df2, on='Key')
输出数据
最后,你可能需要将处理好的数据输出到文件,以供进一步分析或报告。
# 写入到CSV文件
df.to_csv('processed_data.csv')
# 写入到Excel文件
df.to_excel('processed_data.xlsx')
结语
通过上述内容的介绍,我们了解到Pandas是一个非常强大的库,它能够帮助我们以非常高效的方式来处理和分析数据。上手Pandas并不难,但要真正掌握它,则需要不断地实践和探索。
希望这篇博客能够帮助你开始使用Pandas进行数据分析,并激发你探索更多高级功能的兴趣。Happy Data Analyzing!